
Why Your SCADA and ERP Systems Are Holding Your AI Strategy Hostage — And How to Break Free
A Strategic Guide for Oil, Gas & Energy Executives on Data Fragmentation, AI Readiness, and the Path to Operational Intelligence
Imagine a $500,000-per-hour problem hiding in plain sight. That is precisely what unplanned downtime costs an average oil and gas facility today, a figure that has more than doubled over the past two years. Now imagine that your organization has already invested millions of dollars in a network of SCADA sensors, a modern ERP platform, and the beginnings of an AI strategy — yet your data scientists cannot get a clean, unified dataset to work with.
This is not a technology failure. It is a data architecture failure, and it is endemic across the energy sector. Across upstream wellheads, midstream pipelines, and downstream refineries, the industry is sitting on an ocean of operational data while most AI initiatives remain marooned in pilot purgatory, unable to scale, unable to deliver, and unable to justify the next round of investment. The real barrier is not the algorithm. It is the fragmented, siloed, and context-poor state of your enterprise data — and understanding that barrier is the first step to resolving it.
The Data Landscape in Oil & Gas: A Tale of Two Worlds
The modern oil and gas enterprise operates across two fundamentally different data universes that were never designed to speak to each other. The first is the Operational Technology (OT) world: SCADA systems, distributed control systems (DCS), process historians, and IoT sensor networks that capture real-time physical parameters — pressure, temperature, flow rate, vibration — at millisecond intervals. A single offshore platform today generates between one and two terabytes of raw operational data every day, compared with just 10 to 15 gigabytes a decade ago.
The second universe is the Information Technology (IT) world: ERP systems for supply chain management, maintenance planning, procurement, finance, and workforce management. These systems hold the business context — work orders, asset registries, cost codes, regulatory compliance records, and procurement histories — that give meaning to the raw operational numbers.
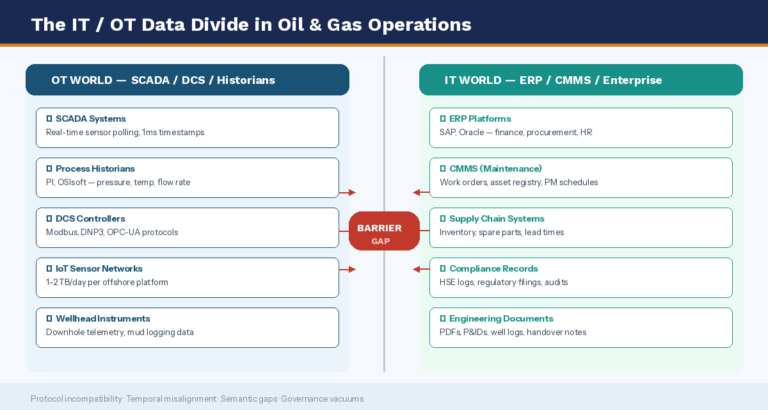
The Core Problem
SCADA tells you that pump bearing #7 on Platform Alpha is running 4°C above baseline. Your ERP tells you that the last scheduled maintenance was seven months ago and a replacement bearing is on backorder. But neither system tells the other — and your AI model only sees half the picture.
This IT/OT divide is the structural fault line beneath virtually every failed AI initiative in energy. According to McKinsey’s 2024 research, 70% of oil and gas companies remain stuck in the pilot phase despite multi-year investments in digital technologies. The average digital maturity score across global oil and gas companies stands at only 2.3 out of 5.0. The culprit, consistently, is data fragmentation.
70% | of oil and gas companies remain stuck in the pilot phase despite years of digital investment. (McKinsey, 2024) |
80% | of AI project failures in industrial settings are caused by poor data quality. (Industry Research, 2025) |
$250B | in value could be unlocked for upstream oil and gas through digitized, AI-enabled operations by 2030. (Industry Analysis) |
Understanding SCADA-ERP Data Fragmentation: The Five Fault Lines
Data fragmentation in oil and gas is not a single problem — it is a constellation of interconnected architectural weaknesses that compound each other. Understanding these fault lines is essential before any remediation can succeed.
Protocol Incompatibility: SCADA systems speak Modbus, DNP3, and OPC-UA. ERP systems speak SQL, REST APIs, and proprietary data schemas. Without deliberate integration middleware, these systems exchange no data at all. Legacy SCADA deployments — many of which are 15 to 25 years old — were built in an era when operational data was never intended to leave the plant floor. Connecting them to modern enterprise systems requires significant engineering effort and introduces cybersecurity risks that many organizations are not yet equipped to manage.
Temporal Misalignment: SCADA data is timestamped at the millisecond level. ERP transactions may be recorded hours, days, or even weeks after the fact. When an AI model tries to correlate a process anomaly detected at 14:32:07 on a Tuesday with the maintenance work order that preceded it, it is attempting to join datasets operating at completely different temporal resolutions. This misalignment silently corrupts predictive models and produces false correlations that erode trust in AI-generated recommendations.
Semantic Gaps: An asset might be called “P-407” in the SCADA historian, “Pump 407 — Crude Transfer” in the ERP asset registry, and “Asset 00734” in a compliance management system. Without a master data layer that resolves these identities, automated data pipelines break down, and engineers spend hours manually reconciling records that should be linked automatically. Studies show that semantic inconsistency alone accounts for a significant share of data quality failures in energy operations.
Unstructured Data Silos: An EY study of a major oil and gas capital projects transformation found that the company had a library of more than 750 engineering documents, each containing upwards of 100 cross-referenced requirements — all in unstructured formats completely inaccessible to AI systems. Inspection reports, well logs, incident records, drilling journals, and handover notes exist in PDFs, spreadsheets, emails, and shared drives that no analytics platform can read without prior processing. This unstructured data often contains the most operationally valuable institutional knowledge in the entire organization.
Governance and Ownership Vacuums: In most energy organizations, SCADA data is owned by operations, ERP data is owned by IT, and well data is owned by engineering. No single team is accountable for the quality, integration, or AI-readiness of the combined data estate. Without unified data governance, critical datasets degrade silently — fields go unpopulated, timestamps drift, units of measurement go inconsistent — until the moment an AI project depends on them.
Why Data Quality Is the Prerequisite — Not the Afterthought, for AI
The energy industry has been sold a compelling vision: AI models that predict equipment failures weeks in advance, optimize production rates in real time, reduce methane emissions, and cut maintenance costs by 40%. This vision is achievable. But achieving it requires a foundation that most organizations have not yet built.
The reason is straightforward: AI models are only as intelligent as the data context they can access. A predictive maintenance model trained on incomplete sensor data will generate unreliable failure predictions. A production optimization algorithm that cannot see procurement lead times from the ERP will recommend interventions that are operationally impossible. A generative AI assistant asked to explain a process anomaly will hallucinate causes if it lacks access to the relevant historical maintenance records.
The Context Imperative
AI does not just need data — it needs connected, contextualized data. A temperature reading without equipment history, maintenance context, and process parameters is noise. The same reading embedded in a rich operational context becomes a predictive signal worth millions.
This is what the industry means by data readiness: not merely the presence of data, but its fitness for AI consumption. Data readiness encompasses quality, structure, accessibility, governance, and semantic coherence. Without it, even the most sophisticated AI model deployed on the most powerful cloud infrastructure will fail to deliver meaningful operational value.
Shell’s deployment of AI-driven predictive maintenance has demonstrated 20% reductions in unplanned downtime and 15% cuts in maintenance costs — but only after establishing robust data integration pipelines that connected SCADA sensor streams to ERP maintenance histories. BP’s partnership with Palantir to build AI-powered operational decision support required deploying large language models across an integrated digital twin of BP’s global operations — not across fragmented, disconnected data stores. These are not just technology success stories. They are data architecture success stories.
A Practical Guide to Achieving Data Readiness: The Six Steps
The path from fragmented SCADA-ERP data to AI-ready operational intelligence is not a single leap. It is a structured progression that requires both technical execution and organizational alignment. Here is a proven framework for energy companies ready to move beyond the pilot phase.
Step 1 — Conduct a Baseline Data Readiness Assessment
Before investing in any AI initiative, map your current data estate. Identify every operational data source — SCADA historians, ERP modules, CMMS platforms, well data systems, environmental monitoring systems — and evaluate each against key readiness dimensions: completeness, accuracy, timeliness, consistency, and accessibility. This assessment will surface the highest-risk data gaps and help prioritize remediation investment. Organizations that skip this step routinely discover their data problems only after a failed AI deployment, at far greater cost.
Step 2 — Establish a Master Data Management (MDM) Layer
Build a canonical master data layer that resolves asset identities, standardizes units of measurement, and maps terminology across SCADA, ERP, and all other operational systems. This layer is the semantic bridge that makes cross-system AI queries possible. Without it, every analytics project requires custom data reconciliation work that consumes more time than the actual modeling.
Step 3 — Implement Secure OT/IT Data Integration
Deploy controlled integration architecture — including data diodes, demilitarized zones (DMZs), and API gateways — that enables operational data from SCADA and process historians to flow securely into enterprise analytics platforms without exposing control systems to cybersecurity risk. This is a non-negotiable prerequisite for any AI initiative that requires real-time operational context.
Step 4 — Digitize and Structure Unstructured Knowledge Assets
Prioritize the conversion of unstructured operational knowledge — inspection reports, well logs, engineering documents, incident records — into structured, AI-accessible formats. Modern document intelligence pipelines can automate much of this conversion. One major oil company achieved 90% efficiency savings versus manual processing through AI-powered document ingestion and metadata tagging, unlocking $5 million in productivity gains from previously inaccessible institutional knowledge.
Step 5 — Implement Continuous Data Quality Monitoring
Data readiness is not a one-time project — it is an ongoing operational discipline. Deploy automated data quality monitoring that tracks completeness, accuracy, and freshness of critical datasets in real time, and establish clear accountability for data quality within operational teams. The goal is to catch data degradation before it contaminates an AI model, not after.
Step 6 — Align AI Use Cases to Actual Data Maturity
The most common cause of AI pilot failure in energy is the misalignment between an ambitious use case and the actual maturity of the underlying data. Before committing to any AI initiative, evaluate the feasibility of that specific use case against your current data readiness scores. Prioritize use cases where data quality and accessibility are already strong, build early wins, and use those wins to fund the data infrastructure improvements needed for more complex applications.
The Competitive Stakes: Why This Matters Right Now
The energy industry is entering a pivotal window. <From 2025 to 2030, digitizing upstream operations alone could unlock $250 billion in value. The AI and machine learning market within oil and gas — valued at $2.5 billion in 2024 — is projected to reach nearly $8 billion by 2034. Companies that establish AI-ready data foundations today will compound their operational advantage every year. Those that do not will find themselves competing against peers who can optimize production in real time, predict failures weeks in advance, and make capital allocation decisions with a level of analytical precision that manual processes simply cannot match.
Only 17% of large energy companies have fully completed their digital transformation journeys. The majority are still in progress or lagging. This means the window for competitive differentiation remains open — but it is closing. The organizations that act now to resolve data fragmentation and build genuine AI readiness will define the operational benchmarks that everyone else will be measured against for the next decade.
Where to Start: Knowing Your Data Readiness Score
Resolving SCADA-ERP data fragmentation at scale requires a precise understanding of where your data estate stands today — not a general sense, but a quantified, dimension-by-dimension diagnostic that tells you exactly which data assets are AI-ready, which require remediation, and which use cases are feasible right now versus which require foundational work first.
This is the challenge that DeepRoot AI was built to solve.
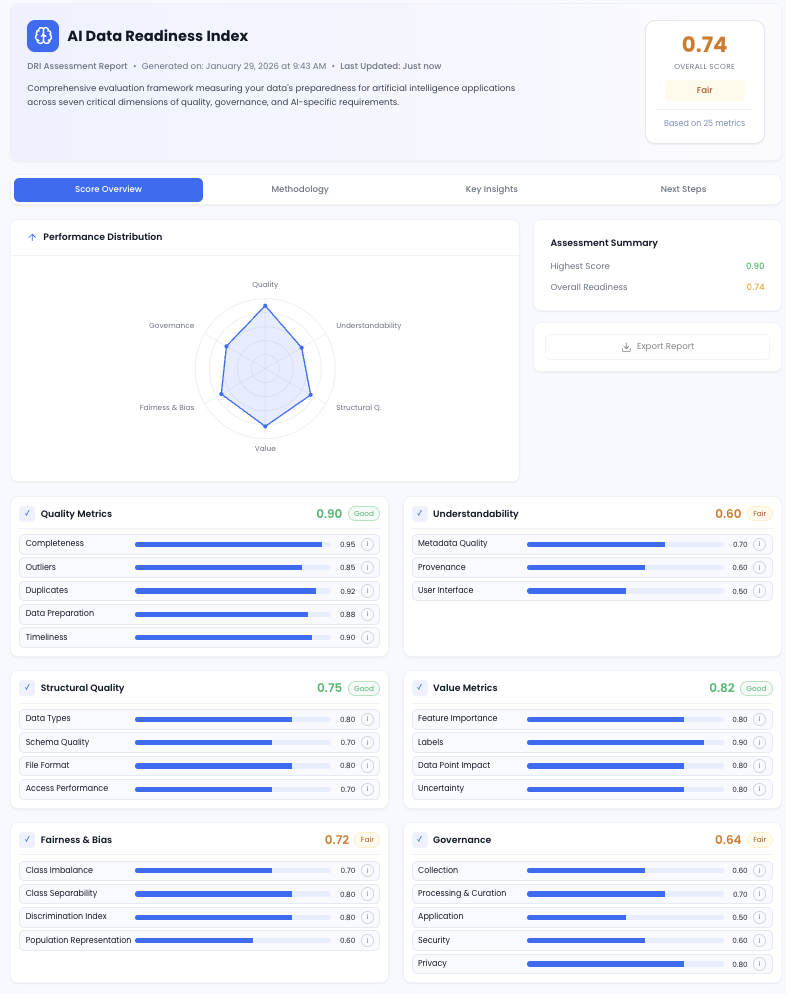
DeepRoot AI — Data Readiness Index (DRI)
DeepRoot AI’s Data Readiness Index (DRI) is a multi-dimensional scoring engine that quantifies your enterprise data’s AI suitability across seven critical categories:
- Quality — completeness, duplication, and timeliness of operational records
- Understandability — metadata, data provenance, and contextual clarity
- Structural Integrity — schemas, formats, and access latency across OT/IT layers
- Value Metrics — feature labeling, impact scoring, and uncertainty quantification
- Fairness & Bias — class imbalance and discrimination risk in AI models
- Governance — collection standards, security, privacy, and usage controls
- AI Fitness — robustness, explainability, and alignment to model constraints
The DRI output delivers numeric scores and diagnostic insights per domain, helping energy companies de-risk GenAI deployments and prioritize use cases based on actual data feasibility, not wishful thinking.
For oil and gas and energy organizations, DeepRoot AI’s DRI assessment is specifically designed to evaluate the complex, multi-system data environments that characterize the industry. It connects across SCADA historians, ERP systems, CMMS platforms, well data systems, and document repositories to produce a unified data readiness score — giving executive and technical teams a shared, quantitative language for data quality conversations that previously relied on opinion and anecdote.
The DRI does not just identify problems. It prioritizes them. By scoring each data domain against AI fitness criteria, it tells you which investments in data quality will deliver the highest return on your AI initiatives — and which pilot projects are built on data foundations strong enough to actually scale.
Conclusion: AI Readiness Begins with Data Readiness
The oil and gas industry has never lacked ambition in its AI strategy. What it has consistently lacked is the data foundation to execute that strategy at scale. SCADA systems that cannot talk to ERP platforms, operational data trapped in unstructured documents, semantic inconsistencies that corrupt cross-system analytics, and governance vacuums that allow data quality to silently deteriorate — these are not peripheral technical problems. They are existential threats to the AI investments that the entire industry is making.
The companies that will lead the next decade of energy operations are not necessarily the ones with the most advanced algorithms. They are the ones that have done the unglamorous but essential work of building AI-ready data infrastructure. They know what their data is worth, where it lives, what shape it is in, and what it needs to support the AI use cases that will define their competitive position.
The question is no longer whether your organization needs AI. It is whether your data is ready to support it. Find out where your data stands today.
CHECK YOUR DATA READINESS
Assess your organization’s AI readiness with DeepRoot AI’s Data Readiness Index (DRI). Get a quantified, dimension-by-dimension diagnostic of your SCADA, ERP, and operational data estate — and know exactly which AI use cases your data can support right now. Visit deeproot.ai to begin your assessment.