
On-Premises vs. Cloud-Based LLM: The Definitive Guide to Enterprise GenAI Deployment
Generative AI has moved from hype to the heart of enterprise strategy. The real question isn’t if you’ll deploy it, but where. As this technology evolves from experimental projects into mission-critical infrastructure, leadership confronts a pivotal architectural decision: where to deploy the Large Language Models (LLMs) that power this revolution. The choice between the secure fortress of an on-premises data center and the vast, elastic cloud is the new strategic frontier, profoundly impacting security, financial models, innovation velocity, and competitive standing.
Understanding the Core Architectures: A Primer for AI Leaders
Before architecting a solution, a clear understanding of the two fundamental deployment paradigms for any Generative AI project is essential.
What is an On-Premises LLM?
An on-premises LLM is your own private power plant. It’s an AI model that you host and operate entirely on your private infrastructure, where the models, data, and high-performance servers hum inside your racks. This architecture provides the highest level of control over data location and access, as your most sensitive information never has to traverse an external network. It’s the choice for organizations where a single data leak is unacceptable.
What is a Cloud-Based LLM?
A cloud-based LLM is an AI model accessed as a managed service, analogous to plugging into an immense, elastic power grid. You interact with the LLM via an API, while the provider manages all the underlying hardware, software frameworks, and maintenance, giving you instant, scalable access without the burden of building the plant yourself. This model is governed by flexible consumption models, from dedicated capacity for high-volume use to pay-as-you-go access for maximum agility.
The Real-World Dilemma: A Strategic Crossroads for Every Enterprise
This isn’t a theoretical exercise; it’s a scenario playing out in boardrooms today. We’ve seen global banks choose on-premises to keep proprietary trading models ultra-fast and compliant, while consumer brands rely on cloud agility to launch global campaigns overnight.
To make this tangible, consider the classic impasse at a company we’ll call Company A
In one corner, the Chief Risk Officer is pounding the table, warning that a single data misstep with their new AI-powered financial tool could cost millions in regulatory fines and shatter client trust. In the other, the Chief Marketing Officer knows that waiting three months to build infrastructure will hand a key market to a nimble competitor. Both are right, and that’s the central conflict leaders must resolve.
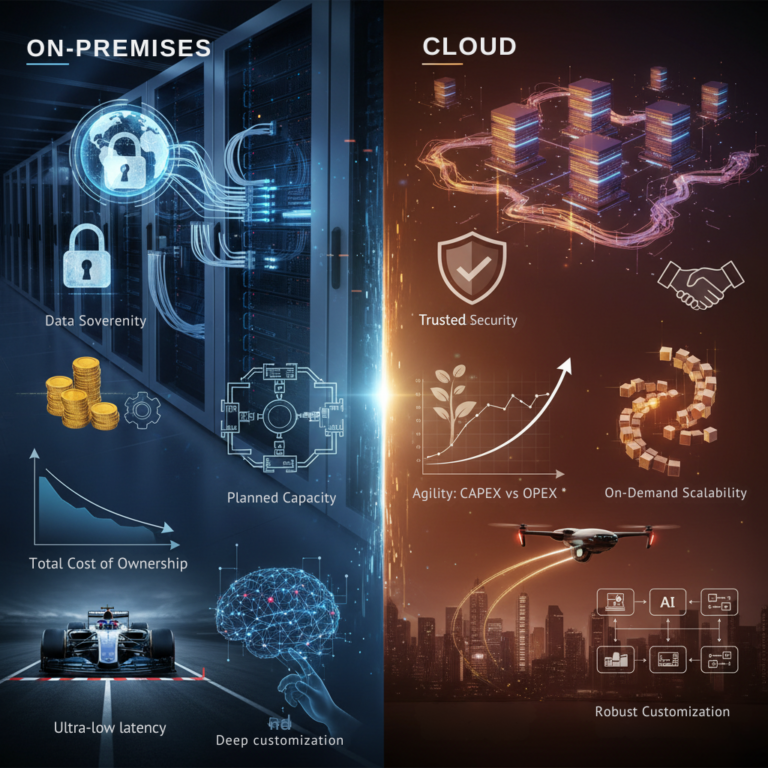
On-Premises vs. Cloud LLMs: A Strategic Comparison for GenAI Projects
The Company A scenario proves there is no single “best” answer. The optimal choice depends on the specific goals of each Generative AI project. Here is a direct comparison across the most critical vectors.
Data Sovereignty and Security Posture
This is the defining difference. An on-premises LLM offers the maximum level of control over data location and access. By ensuring sensitive information never leaves your secure perimeter, it provides the highest level of assurance, which is non-negotiable for regulated industries or for protecting core intellectual property. A cloud-based LLM, while compliant with numerous industry-standard security certifications, operates on a basis of shared trust and requires your data to be processed externally.
The Verdict: On-premises for maximum control; Cloud for trusted, certified environments.
Economic Models: CapEx vs OpEx
The financial approaches are fundamentally different. Deploying an on-premises LLM requires a significant upfront capital expenditure (CapEx). For high-volume, predictable workloads, this can result in a lower total cost of ownership (TCO). However, this ROI is heavily dependent on high GPU utilization; an idle on-premises cluster, like a fleet of parked Ferraris, can quickly become a costly liability. The cloud-based LLM flips this, offering minimal upfront CapEx. Its pay-as-you-go operational expenditure (OpEx) model is ideal for rapid deployment, but costs can escalate with continuous, high-volume use.
The Verdict: On-premises for predictable high-use TCO; Cloud for agility and avoiding capital outlay.
Architectural Elasticity and Scalability
Here, the cloud holds a distinct advantage. A cloud-based LLM architecture provides near-infinite, on-demand elasticity. You can scale compute resources in minutes to handle fluctuating demand. On-premises LLM scalability is rigid and must be planned far in advance. Scaling up involves a lengthy procurement cycle, making it difficult to respond to sudden market opportunities.
The Verdict: Cloud for on-demand, near-infinite scale; On-premises for planned, predictable capacity.
Performance and Latency
For most enterprise use cases, cloud-based LLMs can rival or even surpass on-premises deployments in performance, benefiting from state-of-the-art GPUs and optimized model serving. However, for ultra-low-latency workloads, such as in high-frequency trading or real-time manufacturing automation, on-premises can hold a distinct advantage by eliminating network hops entirely.
The Verdict: Cloud for state-of-the-art inference speed; On-premises for ultra-low-latency, network-independent consistency.
Model Customization and Competitive Differentiation
An on-premises LLM grants an enterprise the highest degree of control to shape a true competitive advantage through deep fine-tuning of open-source models on proprietary datasets. Realizing this potential, however, demands significant in-house MLOps expertise. Cloud providers are rapidly expanding their customization capabilities with offerings such as retrieval-augmented generation (RAG) and fine-tuning of open-weight models. To deliver meaningful value, these services must also support proprietary datasets and competitive models, relieving enterprises of operational burden while still enabling differentiation.
The Verdict: On-premises for deep model differentiation; Cloud for robust customization without the operational overhead.
The Emerging Gold Standard: The Hybrid AI Strategy
As the leaders at Company A would discover, the most effective path forward is not an “either/or” decision. The most advanced strategy being adopted is the Hybrid AI Model. Think of it as a hybrid vehicle, you switch seamlessly between the efficiency of the public grid and the power of your own engine, depending on the demands of the journey.
A hybrid architecture creates an intelligent ecosystem that leverages the strengths of both models, allowing an organization to:
- Run sensitive, regulated workloads on a secure on-premises LLM.
- Leverage the agility of a cloud-based LLM for public-facing applications.
Successfully implementing this strategy, however, requires sophisticated orchestration and governance layers to manage data pipelines and ensure consistent compliance across both environments, preventing operational fragmentation.
The Road Ahead: Beyond the Binary Choice
Looking forward, expect a surge in hybrid orchestration platforms that make this decision less binary. Within the next 24 months, the question will shift from on-premises vs. cloud to how do we run both intelligently within a unified governance framework?
Conclusion: Architecting Your Enterprise AI Blueprint
The deployment choice for your Generative AI initiatives is one of today’s most consequential strategic decisions. The goal is not to choose one over the other, but to architect a sophisticated and resilient AI infrastructure that propels all your business ambitions forward.
Every quarter spent debating architecture is a quarter your competitors are deploying and getting ahead. The real challenge is engineering the intelligent fabric that connects these disparate requirements. This is where a deep, strategic partnership becomes invaluable.
At Innoflexion, we specialize in crafting these bespoke Generative AI blueprints. We help enterprise leaders move beyond the deployment debate to design and implement robust, hybrid AI ecosystems that deliver both security and a definitive competitive edge. If you are ready to build an AI foundation that is as secure as it is agile, explore Innoflexion’s GenAI services and discover how we can help you architect the future of your business.