
What Is a Data Readiness Index (DRI)? The Complete Enterprise AI Guide
Every enterprise investing in AI right now is making a bet. While you likely know exactly how much you are spending on models and engineering hours, the actual odds of the project succeeding are often completely unknown. A Data Readiness Index is how you calculate that probability. It measures exactly how AI-ready your enterprise data is—before you spend a single dollar building anything.
→ Check your data architecture scoreIf you are leading an enterprise AI initiative today, there is an uncomfortable truth you need to confront: the vast majority of projects stall out before they ever reach production. The culprit usually isn't choosing the wrong model or struggling with an API integration. The failure happens right at the foundation, when teams realize the data powering the AI system isn't actually ready to support it.
This failure is incredibly predictable—and entirely preventable. Organizations that pause to measure their data readiness before committing to an AI build deploy faster, spend far less on unexpected remediation, and create AI tools that actually work in production. Those who skip this step are, statistically speaking, more likely to abandon their projects altogether.
This guide explains exactly what a Data Readiness Index is, what it measures, why it’s critical for avoiding costly failures, and how it can empower you to make smarter enterprise AI investments.
These numbers paint a stark picture. Too many organizations are pouring money into AI while flying completely blind regarding their data's health. They’re hoping their data is structurally sound enough for AI, semantically coherent enough for retrieval systems, and governed tightly enough for autonomous agents. A Data Readiness Index takes the guesswork out of the equation.
What Is a Data Readiness Index?
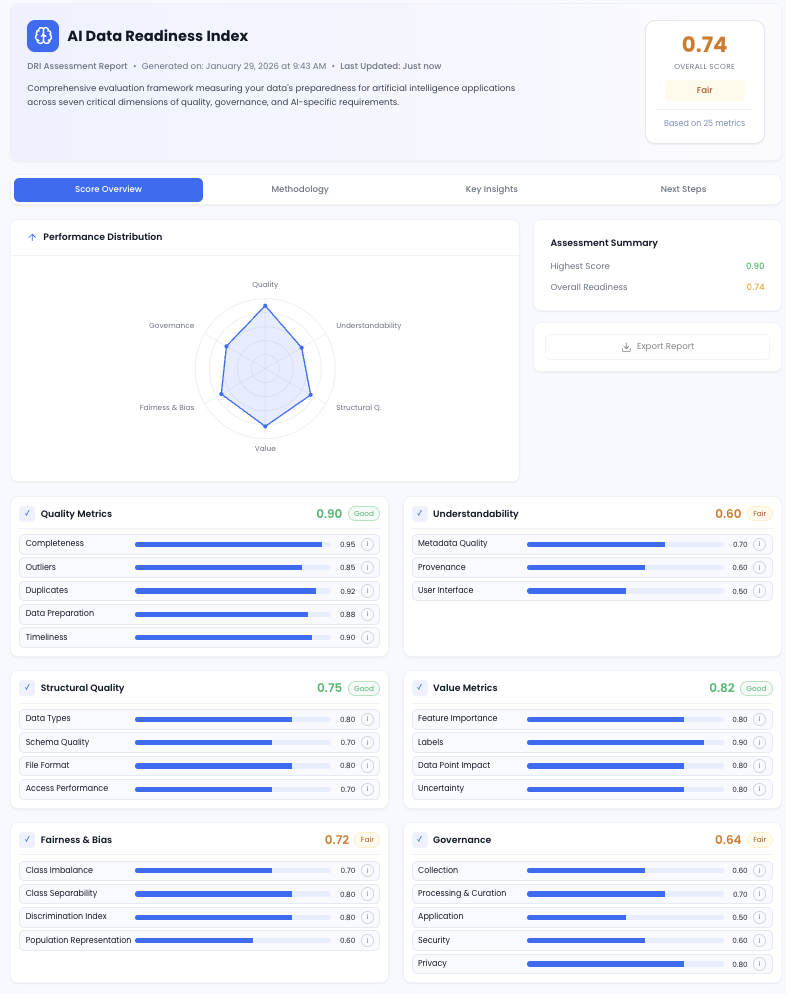
A Data Readiness Index (often abbreviated as DRI) is a structured, quantified assessment that evaluates how prepared your enterprise data is to support AI deployment. Instead of a simple pass/fail grade, a DRI generates numeric scores on a scale of 0.1 to 1.0. It spans multiple dimensions, including quality, governance, structural integrity, semantic alignment, and overall AI fitness. The result is a precise map telling you exactly which data sources can power AI today, and which ones need immediate remediation.
You might be wondering, "Isn't this just a traditional data audit?" Not quite. A conventional data audit asks: Is this data accurate enough for our quarterly reports? A Data Readiness Index asks: Is this data accurate, complete, governed, and semantically consistent enough for an AI system that will actively make—or directly inform—business decisions? The former ensures trustworthiness for human readers. The latter guarantees safety for algorithmic execution.
Why this distinction matters: The World Economic Forum's recent executive briefings repeatedly identify data readiness as the number one AI priority for global CEOs—ranking above model selection or talent acquisition. Generative and agentic AI systems demand more than just smart models; they require clean, integrated, and intensely governed enterprise data to deliver real business value. A DRI is how you measure whether you've met that standard.
Because the DRI produces scores on a 0.1 to 1.0 scale across your specific data sources and departments, it becomes an incredibly actionable tool. It doesn't just tell you that your data is messy—it pinpoints exactly where the vulnerabilities lie and how severe they are for your specific AI goals.
The 7 Dimensions DeepRoot's DRI Measures
Different frameworks measure different things, but DeepRoot's DRI was designed exclusively for the realities of modern enterprise AI—including complex RAG systems, agentic workflows, and LLM orchestration. We score your data across seven dimensions that consistently dictate whether an AI project will succeed or stall.
-
01
Data Quality
This is your foundation. We look at the completeness, accuracy, consistency, and timeliness of your data. Think duplicate detection, missing fields, and cross-record consistency. IBM's Institute for Business Value found that many organizations lose millions annually purely due to poor data quality—before an AI system even amplifies those errors. We quantify this risk for you.
Foundation Dimension -
02
Understandability (Metadata Richness)
AI retrieval systems rely heavily on metadata to figure out what a document is, who owns it, and when it was last updated. Without rich, consistent tagging, retrieval precision collapses. The AI will grab documents based purely on semantic similarity, ignoring critical context like authority or recency. This dimension scores how well your metadata is structured to support these systems.
Retrieval Critical -
03
Structural Integrity
Enterprise AI almost never lives in just one system. It pulls from CRMs, ERPs, shared drives, and email archives. When the schemas and data types between these systems don't match up, multi-source reasoning breaks down. The AI simply cannot reconcile the differences. This dimension maps your cross-system structural coherence to prevent large-scale retrieval failures.
Architecture Risk -
04
Value Metrics (Feature Relevance)
Just because data exists doesn't mean it's useful for AI. A dataset might be perfectly clean but completely irrelevant to the questions your users will actually ask. We assess feature coverage, labeling completeness, and the overall signal-to-noise ratio to ensure you are feeding your AI information that matters.
Use Case Fit -
05
Fairness and Bias
If you ground an AI in biased data, it will invisibly reproduce and amplify those biases. We look for class imbalances and representation gaps that introduce discrimination risk. With strict regulations like the EU AI Act demanding documented bias assessments for high-risk systems, a strong score here is essential for regulatory compliance.
Compliance Critical -
06
Governance (Lineage and Controls)
Does your data have the proper access controls, provenance tracking, and usage policies? For agentic AI—where autonomous agents take actions across systems—governance is not optional. It is the only safety net preventing agents from accessing restricted data or executing unauthorized actions. Without a high governance score, you simply cannot audit your AI's outputs.
Governance Critical -
07
AI Fitness (Semantic Coherence)
This evaluates whether the language inside your data matches the language your users will use to search. If your database labels a product "SKU-4821-B," but your sales team asks the AI about the "legacy thermal model," the AI will fail to bridge that gap. We score how well your internal vocabulary aligns with real-world query patterns.
AI Retrieval Risk
DRI Score Benchmarks by Industry
Before launching an assessment, clients frequently ask us: What's a normal score for a company like ours? Based on DeepRoot's deployments across healthcare, finance, education, and manufacturing, we’ve mapped out the typical ranges you can expect. Keep in mind, these benchmarks (scored from 0.1 to 1.0) are just baselines. Your actual score will depend on your specific systems and historical data investments.
| Industry | Avg. Overall DRI | Strongest Dimension | Weakest Dimension | Primary Gap |
|---|---|---|---|---|
| Healthcare | 0.68–0.76 | Governance 0.82–0.90 | AI Fitness 0.55–0.65 | Semantic alignment (clinical codes vs. natural language) |
| Financial Services | 0.65–0.74 | Data Quality 0.80–0.90 | Structural Integrity 0.58–0.70 | Multi-ERP schema incoherence |
| Education | 0.60–0.70 | Data Quality 0.75–0.85 | Structural Integrity 0.48–0.60 | Cross-platform identity resolution (SIS, LMS, CRM) |
| Manufacturing | 0.62–0.72 | Structural Integrity 0.78–0.88 | Understandability 0.48–0.62 | Metadata richness (sensor codes vs. business descriptions) |
| Professional Services | 0.55–0.65 | Value Metrics 0.65–0.75 | Governance 0.45–0.58 | Data lineage gaps across client project systems |
Interpreting your benchmark: A DRI score above 0.75 across the board means that data source is primed for autonomous AI deployment. If you land in the 0.60–0.74 range, you can likely fix the gaps with a focused 4-to-8 week remediation program. However, a score below 0.60 is a clear warning sign: structural fixes are required before you invest heavily in an AI rollout.
Why Traditional Data Audits Fall Short
A common trap enterprise leaders fall into is assuming their standard annual audits or data catalogs have already solved this problem. Unfortunately, traditional data audits were designed for an entirely different era. They measure quality for human reporting and regulatory compliance—not for vector embeddings, multi-agent reasoning, or semantic retrieval.
| Dimension | Traditional Data Audit | Data Readiness Index (DRI) |
|---|---|---|
| Purpose | Reporting accuracy and compliance | AI deployment readiness |
| Methodology | Manual, periodic, retrospective | Automated, continuous, forward-looking |
| Output | Qualitative report and checklist | Numeric score (0.1–1.0) per dimension, per source |
| Metadata evaluation | ✗ Not assessed for AI suitability | ✓ Richness scored for retrieval |
| Semantic alignment | ✗ Not evaluated | ✓ Mapped to user query patterns |
| Cross-system coherence | Partial — schema only | ✓ Full multi-source mapping |
| Agentic AI safety | ✗ Not considered | ✓ Governance lineage for agent actions |
| Bias assessment | Limited — compliance-focused only | ✓ AI-specific discrimination risk scoring |
| Time to complete | 6–12 weeks (manual) | ✓ 2–4 weeks (automated) |
| Data movement required | Often — data must be extracted | ✓ Metadata ingestion only |
The scaling fallacy: Just because an AI model works brilliantly in a pilot phase on carefully sanitized data doesn't mean it's ready for enterprise production. The real world is messy, siloed, and structurally complex. A DRI surfaces the reality of your data estate *before* you attempt to scale and hit a wall.
Don't assume your data is AI-ready. Measure it.
DeepRoot's DRI gives you a numeric score (0.1–1.0) across all 7 dimensions in just 14 days — with absolutely no data movement or operational disruption.
Why the DRI Matters More in 2026 Than Ever Before
The conversation around AI is shifting fast, and three major forces have turned data readiness from a "nice-to-have" into a strategic absolute.
1. The Shift to Agentic AI Raises the Stakes
With standard generative AI, if the system hallucinates an answer, a human spots the error and moves on. The failure is contained. But agentic AI acts autonomously—processing invoices, updating records, triggering orders. If it acts on bad data, the error is immediately executed across your downstream systems. Agentic AI's power is its autonomy, making a low DRI score a serious operational liability.
2. Governance is Now a Board-Level Conversation
Because agentic AI takes action, data governance is under intense scrutiny. To run agents safely, your data must have rigid access control lineage (so agents don't access what they shouldn't), action auditability (so you can trace every decision back to its source), and strict freshness guarantees (so agents aren't acting on stale metrics). In our assessments, governance is the dimension that most frequently falls below the required 0.70 safety threshold.
What the data shows: Organizations that try to deploy agentic workflows on data sources with a governance score below 0.60 consistently experience compounding errors within the first month. And because the system acts autonomously, those errors propagate rapidly.
3. Tightening Global Regulations
With frameworks like the EU AI Act now highly active, alongside tightening HIPAA and SEC guidelines, organizations are required to prove their AI systems are bias-assessed and heavily governed. A DRI provides the documented, empirical evidence that auditors and regulators look for.
4. Rework Is Extremely Expensive
Finding out your data is flawed midway through an AI integration typically adds 3 to 6 months of delays and up to $380,000 in unplanned costs. As we outlined in our RAG guidelines, investing a small amount of time upfront to assess readiness prevents massive budgetary blowouts later.
"AI-ready data is not a one-time task. It is a continuous process that requires organisations to improve their data management infrastructure as AI use cases evolve."
Gartner ResearchDRI in Practice: What It Looks Like in the Wild
Here is how the DRI plays out across the diverse industries we serve.
Claims Processing & Document Intelligence
Healthcare requires sky-high scores in governance (HIPAA) and fairness. Our DRIs often find that while the data is structurally sound, semantic alignment is poor (clinical codes don't match conversational language). Remediation focuses heavily on terminology translation. Average overall DRI: 0.68–0.76.
95% automation accuracy post-DRIInvoice Processing & Compliance AI
In finance, a bad AI action costs real money instantly. DRIs here frequently uncover schema mismatches across massive, multi-ERP setups. Fixing governance trails for SOX compliance is usually priority number one. Average overall DRI: 0.65–0.74.
60% faster processing post-DRI deploymentAcademic Operations & Learning Intelligence
Universities often suffer from highly siloed data (separate SIS, LMS, and CRM systems). While records are complete, cross-system identity resolution is weak. Remediation focuses heavily on unifying student profiles. Average overall DRI: 0.60–0.70.
60% admin time saved post-deploymentPredictive Maintenance & Inventory AI
IoT sensors provide great structured data, but the metadata is often severely lacking—a string of numbers without business context. Furthermore, data freshness issues often block real-time predictive models. Average overall DRI: 0.62–0.72.
Predictive accuracy 85%+ on DRI-validated dataHow DeepRoot Runs a DRI Assessment
We designed the DeepRoot DRI process to be lightweight, secure, and rapid. From kick-off to your final roadmap, the entire process takes just 14 days, and we never move your underlying business data.
-
1
Source System Mapping (Days 1–2)
We start by mapping the terrain. We identify every CRM, document store, and database relevant to your AI goal, documenting the data owner, update frequency, and expected role in the AI workflow.
-
2
Automated Metadata Ingestion (Days 3–7)
DeepRoot's connectors ingest *only* metadata—schema structures, timestamps, access controls, and field definitions. No raw business data ever leaves your environment, making this highly secure for regulated industries.
-
3
Multi-Dimensional Scoring (Days 8–12)
Our engine evaluates the metadata across the 7 DRI dimensions. We calculate granular scores (0.1–1.0) and generate diagnostic flags that highlight exactly *why* a score is low, turning vague data problems into specific engineering tasks.
-
4
Readiness Report and Prioritised Roadmap (Days 13–14)
You receive your finalized enterprise DRI score alongside a clear roadmap. We categorize your data into three buckets: ready today, ready with oversight, and needs immediate remediation. This allows your team to confidently sequence your AI builds.
The DeepRoot principle: You don't have to fix everything to start building. Most clients find that 30–40% of their data scores above 0.75 on day one, allowing them to confidently launch their first production use case while remediating other areas in parallel.
Know Your Enterprise DRI Score in 14 Days
Stop crossing your fingers and building on assumed data quality. Get a quantified, dimension-level readiness score for your entire pipeline—without risking data movement.
Deployed across Healthcare · Finance · Education · Manufacturing · No data movement required
Data Readiness Index: Common Enterprise Questions
What is a Data Readiness Index (DRI)? +
A Data Readiness Index (DRI) is a quantified, multi-dimensional assessment that scores how prepared your enterprise data is for AI deployment — including GenAI, RAG systems, and agentic AI workflows. Rather than a qualitative checklist, a DRI produces numeric readiness scores on a scale of 0.1 to 1.0 across dimensions such as data quality, governance, structural integrity, semantic alignment, and AI fitness, giving enterprise teams a clear, actionable picture of where their data is ready to deploy AI today and where remediation is needed first.
Why do enterprises need a DRI before deploying AI? +
Gartner predicts that 60% of AI projects without AI-ready data will be abandoned through 2026. A DRI assessment identifies data quality gaps, governance weaknesses, and structural issues before they become mid-project failures — saving organisations the 3–6 months of rework and massive remediation costs that typically follow discovering data problems after a build has already started. Without a DRI, enterprises make AI investment decisions based on assumed data quality rather than measured data quality.
What dimensions does a Data Readiness Index measure? +
DeepRoot's DRI scores enterprise data across seven dimensions, each rated on a 0.1–1.0 scale: (1) Quality — completeness, accuracy, and timeliness; (2) Understandability — metadata richness and documentation; (3) Structural Integrity — schema consistency across systems; (4) Value Metrics — feature relevance and labelling completeness; (5) Fairness and Bias — representation and discrimination risk; (6) Governance — data lineage, privacy controls, and usage policies; and (7) AI Fitness — semantic coherence with intended AI use cases and user query patterns.
How long does a DRI assessment take? +
DeepRoot's automated DRI assessment takes 2–4 weeks, delivering a scored readiness report with diagnostic insights and a prioritised remediation roadmap within 14 days. The process uses metadata-based ingestion — profiling your enterprise data systems without moving any actual data — making it deployable in high-security environments including healthcare, financial services, and regulated industries.
What is a good DRI score for AI deployment? +
DRI scores are measured on a scale of 0.1 to 1.0 per data source and dimension. Data sources scoring above 0.75 overall are generally considered ready for autonomous AI deployment. Sources scoring between 0.50 and 0.74 may support AI with human review checkpoints in place. Sources below 0.50 typically require structured remediation before they should be included in production AI systems — particularly agentic AI workflows where poor data quality can trigger incorrect actions at scale. Most enterprises find that 30–40% of their planned data estate meets the 0.75 threshold on the first assessment.
Is a DRI different from a traditional data audit? +
Yes — significantly so. A traditional data audit assesses data quality for reporting and compliance purposes. A Data Readiness Index is specifically calibrated for AI deployment requirements: it evaluates semantic alignment with intended AI use cases, retrieval suitability for RAG systems, governance lineage for explainability requirements, and structural coherence across multi-source enterprise systems. A DRI produces quantified, AI-specific readiness scores on a 0.1–1.0 scale — not compliance checklists — and completes in 2–4 weeks rather than the 6–12 weeks a manual audit typically requires.
What are typical DRI score benchmarks by industry? +
Based on DeepRoot's deployments: Healthcare organisations typically score 0.68–0.76 overall, with governance and structural integrity as strengths but semantic alignment as the primary gap. Financial services organisations average 0.65–0.74 overall, with strong data quality but weaker cross-system structural coherence due to multi-ERP complexity. Education institutions average 0.60–0.70 overall, with strong data completeness but weak cross-platform identity resolution. Manufacturing organisations average 0.62–0.72 overall, with strong structured data quality but low metadata richness. The industry benchmarks table earlier in this article provides full dimension-level breakdowns.
Why does agentic AI require stricter data governance than generative AI? +
Agentic AI systems act autonomously — processing invoices, routing claims, triggering procurement orders — without a human reviewing each step. When a generative AI produces a wrong answer, a human catches the error before it propagates. When an agentic AI acts on poorly governed data, the error executes across downstream systems before any human sees it. This is why agentic AI data governance requires access control lineage (defining which data an agent may use), action auditability (tracing every agent decision back to its data source), and data freshness guarantees (ensuring agents cannot act on stale data). A DRI governance score below 0.70 is a red flag for any agentic AI use case — in DeepRoot's deployments, organisations that attempt autonomous agent workflows on governance scores below 0.60 consistently encounter compounding errors within the first four weeks of production.